分类与回归树(classification and regression tree, CART)模型是应用比较广泛的决策树学习方法之一,它既可以用于分类也可以用于回归。CART算法使用二元切分递归地处理每个特征,如果特征值大于给定值就走左子树,否则就走右子树。
最小二乘回归树生成算法
数学描述
假设$X$和$Y$分别为输入和输出变量,并且$Y$是连续变量,给定训练数据集
$$D={(x_1,y_1),(x_2,y_2),…,(x_N,y_N)}$$
生成对应的回归树。
一个回归树对应着输入空间(即特征空间)的一个划分以及在划分的单元上的输出值。假设已将输入空间划分为$M$个单元$R_1,R_2,…,R_m$,并且在每个单元$R_m$上有一个固定的输出值$C_m$,于是回归树模型可以表示为
$$f(x) = \sum_{m=1}^{M}c_mI(x \in R_m)$$
其中函数$I$为指示函数。
当输入空间的划分确定时,可以用平方误差$\sum_{x_i \in R_m}(y_i-f(x_i))^2$来表示回归树对于训练数据的预测误差。用平方误差最小的准则求解每个单元上的最优输出值,可以发现单元$R_m$上的最优$\hat c_m$是$R_m$上所有示例$x_i$对应的输出$y_i$的均值,即
$$\hat c_m=avg(y_i|x_i \in R_m)$$
上面内容讲述了在输入空间划分确定的情况下,如何衡量决策树的效果以及在效果最好的情况下反推每个区域输出值$c_m$。接下来我们来看如何划分输入空间。
首先,CART树是一棵二叉树,所以我们需要选择一个特征$x^{(j)}$和它的取值$s$,作为整个数据集的切分量和切分点,并定义由其切分的两个区域
$$R_1(j,s)=\lbrace x|x^{(j)} \leq s \rbrace和R_2(j,s)=\lbrace x|x^{(j)} \gt s \rbrace $$
然后寻找最优缺切分变量$j$和最优切分点$s$,即求解
$$min_{j,s}[min_{c1}\sum_{x_i \in R_1(j,s)}(y_i-c_1)^2+min_{c2}\sum_{x_i \in R_2(j,s)}(y_i-c_2)^2]$$
- 注:这里是要找到使$R_1$数据的预测误差最小的$c_1$和使$R_2$数据的预测误差最小的$c_2$,之前说过使误差最小的取值就是分别取两个数据集的均值,然后还要保证$R_1$和$R_2$误差和最小。
对于固定的输入变量$j$可以找到最优的切分点$s$:
$$\hat c_1=avg(y_i|x_i \in R_1(j,s)) 和 \hat c_2=avg(y_i|x_i \in R_2(j,s))$$
- 注:简单讲,这里的$c_1$和$c_2$是每次按照切分点$s$分割成两波数据的均值,这里不明白的可以看后面的例子。
遍历所有输入变量,找到最优的切分变量$j$,构成一对$(j,s)$,并依此将输入空间划分为两个区域。接着对每个区域重复上述划分过程,直到满足条件为止。这样就生成了一棵回归树,这样的回归树通常称为最小二乘回归树。
示例
上述数学描述比较晦涩,举个简单的例子,输入数据见下表
| x | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| y | 5.56 | 5.7 | 5.91 | 6.4 | 6.8 | 7.05 | 8.9 | 8.7 | 9 | 9.05 |
- 第一次划分
由于只有$x$一个变量,因此最优切分变量为$x$。接下来假设9个切分点为$[1.5,2.5,3.5,4.5,5.5,6.5,7.5,8.5,9.5]$,计算每个切分点的输出值。如$s=1.5$时,$R_1={1},R_2={2,3,4,5,6,7,8,9,10}$,这两个区域的输出值分别为$c_1=5.56,c_2=\frac{1}{9}(5.7+5.91+6.4+6.8+7.05+8.9+8.7+9+9.05)=7.50$,所以有
| s | 1.5 | 2.5 | 3.5 | 4.5 | 5.5 | 6.5 | 7.5 | 8.5 | 9.5 |
|---|---|---|---|---|---|---|---|---|---|
| $c_1$ | 5.56 | 5.63 | 5.72 | 5.89 | 6.07 | 6.24 | 6.62 | 6.88 | 7.11 |
| $c_2$ | 7.5 | 7.73 | 7.99 | 8.25 | 8.54 | 8.91 | 8.92 | 9.03 | 9.05 |
接下来计算每个切分点的误差,如$s=1.5$时,$loss(s=1.5)=\frac{1}{2}(5.56-5.56)^2+\sum_{i=2}^{10}\frac{1}{2}(y_i-7.5)^2=0+15.72=15.72$,所以有
| s | 1.5 | 2.5 | 3.5 | 4.5 | 5.5 | 6.5 | 7.5 | 8.5 | 9.5 |
|---|---|---|---|---|---|---|---|---|---|
| $loss(s)$ | 15.72 | 12.07 | 8.36 | 5.78 | 3.91 | 1.93 | 8.01 | 11.73 | 15.74 |
其中当$s=6.5$时,$loss(s)$最小,因此第一个划分变量是$j=x,s=6.5$。
$$
T=\begin{cases}
6.24 \quad x \le 6.5 \\
8.91 \quad x \gt 6.5\\
\end{cases}
$$
第二次划分
第一个划分变量将数据集划分成了两部分即$R_1={1,2,3,4,5,6},R_2={7,8,9,10}$,接下来分别在$R_1,R_2$上进行划分。
- 对于$R_1$
| x | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| y | 5.56 | 5.7 | 5.91 | 6.4 | 6.8 | 7.05 |
取切分点$[1.5,2.5,3.5,4.5,5.5]$,对应的输出值为
| s | 1.5 | 2.5 | 3.5 | 4.5 | 5.5 |
|---|---|---|---|---|---|
| $c_1$ | 5.56 | 5.63 | 5.72 | 5.89 | 6.07 |
| $c_2$ | 6.37 | 6.54 | 6.75 | 6.93 | 7.05 |
误差为
| s | 1.5 | 2.5 | 3.5 | 4.5 | 5.5 |
|---|---|---|---|---|---|
| $loss(s)$ | 1.3087 | 0.754 | 0.2771 | 0.4368 | 1.0644 |
所以$s=3.5$时,$loss(s)$最小
假设在生成3个区域后停止划分,那么最终生成的回归树如下:
$$
T=\begin{cases}
5.72 \quad x \le 3.5 \\
6.75 \quad 3.5 \lt x \leq 6.5 \\
8.91 \quad x \gt 6.5\\
\end{cases}
$$
实现
1 |
|
代码详见CART
- 注:此处代码参考《机器学习实战》p161-p164,原书代码中存在错误,这里进行了修改。
分类树生成算法
分类树使用基尼指数选择最优特征,同时决定最优二值切分点。
基尼指数
基尼指数的定义如下,假设有$K$个分类,样本点属于第$k$类的概率为$p_k$,则概率分布的基尼指数为
$$
Gini(p) = \sum_{k=1}^{K}p_k(1-p_k)=1-\sum_{k=1}^{K}p^2_k
$$
对于给定的样本集合$D$,其基尼指数为
$$
Gini(D)=1-\sum_{i=1}^{K}(\frac{|C_k|}{|D|})^2
$$
其中,$C_k$是$D$中属于第$k$类的样本子集,$K$是类的个数。
如果样本集合$D$根据特征$A$是否取某一可能值$a$呗分割成$D_1$和$D_2$两部分,即
$$
D_1 = {(x,y) \in D|A(x)=a}\\
D_2 = D-D_1
$$
则在特征$A$的条件下,集合$D$的基尼指数定义为
$$
Gini(D,A)=\frac{|D_1|}{|D|}Gini(D_1)+\frac{|D_2|}{|D|}Gini(D_2)
$$
基尼指数$Gini(D)$表示集合$D$的不确定性,基尼指数$Gini(D,A)$表示经$A=a$分割后集合$D$的不确定性。基尼指数越大,样本集合的不确定性也就越大,这一点和熵一致。
- 注:CART分类树为什么要使用基尼指数作为选择最优特征的标准呢?因为基尼指数不仅拥有与熵类似的性质,而且计算简便,不用使用log函数。
生成算法
输入:训练数据集$D$,停止计算的条件;
输出:CART决策树
根据训练数据集,从根节点开始,递归地对每个结点进行以下操作,构建二叉决策树
- 设结点的训练数据集为$D$,计算现有特征对该数据集的基尼指数。此时对每个特征$A$,对其可能取值的每个值$a$,根据样本点对$A=a$的测试为“是”或”否“将$D$分割成$D_1$和$D_2$两部分,并计算$A=a$的基尼指数。
- 在所有可能的特征$A$以及它们所有可能的切分点$a$中,选择基尼指数最小的特征及其对应的切分点作为最优特征和最优切分点。依最优特征与最优切分点,从现结点生成两个子结点,将训练数据依特征分配到两个子结点中。
- 对两个子结点递归地调用1、2,直至满足停止条件
- 生成CART决策树
算法停止条件是结点中的样本个数小于预定阈值,或者样本集的基尼指数小于预定阈值(样本基本属于同一类),或者没有更多特征。
示例
数据集合如下:
| ID | 年龄 | 有工作 | 有自己的房子 | 信贷情况 | 类别 |
|---|---|---|---|---|---|
| 1 | 青年 | 否 | 否 | 一般 | 否 |
| 2 | 青年 | 否 | 否 | 好 | 否 |
| 3 | 青年 | 是 | 否 | 好 | 是 |
| 4 | 青年 | 是 | 是 | 一般 | 是 |
| 5 | 青年 | 否 | 否 | 一般 | 否 |
| 6 | 中年 | 否 | 否 | 一般 | 否 |
| 7 | 中年 | 否 | 否 | 好 | 否 |
| 8 | 中年 | 是 | 是 | 好 | 是 |
| 9 | 中年 | 否 | 是 | 非常好 | 是 |
| 10 | 中年 | 否 | 是 | 非常好 | 是 |
| 11 | 老年 | 否 | 是 | 非常好 | 是 |
| 12 | 老年 | 否 | 是 | 好 | 是 |
| 13 | 老年 | 是 | 否 | 好 | 是 |
| 14 | 老年 | 是 | 否 | 非常好 | 是 |
| 15 | 老年 | 否 | 否 | 一般 | 否 |
分别以$A_1$、$A_2$、$A_3$、$A_4$表示年龄、有工作、有自己的房子和信贷4个特征。
求特征$A_1$的基尼指数,以1,2,3表示年龄的值为青年、中年、老年
$$
Gini(D,A_1=1) = \frac{5}{15}[2 \times \frac{2}{5} \times (1-\frac{2}{5})] + \frac{10}{15}[2 \times \frac{7}{10} \times (1-\frac{7}{10})]=0.44\\
Gini(D,A_1=2) = \frac{5}{15}[2\times\frac{3}{5}\times(1-\frac{3}{5})] + \frac{10}{15}[2\times\frac{6}{10}\times(1-\frac{6}{10})]=0.48\\
Gini(D,A_1=3) = \frac{5}{15}[2\times\frac{4}{5}\times(1-\frac{4}{5})] + \frac{10}{15}[2\times\frac{5}{10}\times(1-\frac{5}{10})]=0.44
$$
其中$Gini(D,A_1=1)$和$Gini(D,A_1=3)$最小,所以$A_1=1$和$A_1=3$均可做为$A_1$的最优切分点
求特征$A_2$的基尼指数,以1,2表示有工作和没有工作
$$
Gini(D,A_2=1) = \frac{5}{15}[2\times\frac{5}{5}\times(1-\frac{5}{5})] + \frac{10}{15}[2\times\frac{4}{10}\times(1-\frac{4}{10})]=0.32
$$
$A_2$只有一个切分点即$A_2=1$
求特征$A_3$的基尼指数,以1,2表示有房子和没有房子
$$
Gini(D,A_3=1) = \frac{6}{15}[2\times\frac{6}{6}\times(1-\frac{6}{6})] + \frac{9}{15}[2\times\frac{3}{9}\times(1-\frac{3}{9})]=0.27
$$
$A_3$只有一个切分点即$A_3=1$
求特征$A_4$的基尼指数,以1,2,3表示信贷情况为非常好、好和一般
$$
Gini(D,A_4=1) = \frac{4}{15}[2\times\frac{4}{4}\times(1-\frac{4}{4})] + \frac{11}{15}[2\times\frac{6}{11}\times(1-\frac{6}{11})]=0.36\\
Gini(D,A_4=2) = \frac{6}{15}[2\times\frac{4}{6}\times(1-\frac{4}{6})] + \frac{9}{15}[2\times\frac{5}{9}\times(1-\frac{5}{9})]=0.47\\
Gini(D,A_4=3) = \frac{5}{15}[2\times\frac{1}{5}\times(1-\frac{1}{5})] + \frac{10}{15}[2\times\frac{8}{10}\times(1-\frac{8}{10})]=0.32
$$
其中$Gini(D,A_4=3)$最小,所以$A_4=3$为$A_4$的最优切分点
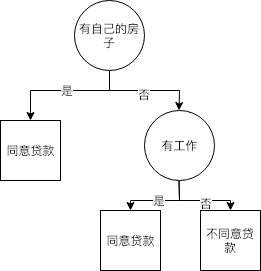
在4个特征中,$Gini(D,A_3=1)=0.27$最小,所以选择$A_3$为最优特征,$A_3=1$为其最优切分点。其中$A_3=1$的结点包含数据4、8、9、10、11,$A_3 \neq 1$结点包含数据1,2,3,5,6,7,13,14,15。$A_3=1$结点内数据类别相同,所以形成叶子结点。对$A_3 \neq 1$结点继续重复上述过程。
数据如下
| ID | 年龄 | 有工作 | 信贷情况 | 类别 |
|---|---|---|---|---|
| 1 | 青年 | 否 | 一般 | 否 |
| 2 | 青年 | 否 | 好 | 否 |
| 3 | 青年 | 是 | 好 | 是 |
| 5 | 青年 | 否 | 一般 | 否 |
| 6 | 中年 | 否 | 一般 | 否 |
| 7 | 中年 | 否 | 好 | 否 |
| 12 | 老年 | 否 | 好 | 是 |
| 13 | 老年 | 是 | 好 | 是 |
| 14 | 老年 | 是 | 非常好 | 是 |
| 15 | 老年 | 否 | 一般 | 否 |
求特征$A_1$的基尼指数
$$
Gini(D,A_1=1) = \frac{4}{10}[2\times\frac{1}{4}\times(1-\frac{1}{4})] + \frac{6}{10}[2\times\frac{3}{6}\times(1-\frac{3}{6})]=0.45\\
Gini(D,A_1=2) = \frac{2}{10}[2\times\frac{0}{2}\times(1-\frac{0}{2})] + \frac{8}{10}[2\times\frac{4}{8}\times(1-\frac{4}{8})]=0.4\\
Gini(D,A_1=3) = \frac{4}{10}[2\times\frac{3}{4}\times(1-\frac{3}{4})] + \frac{6}{10}[2\times\frac{1}{6}\times(1-\frac{1}{6})]=0.32
$$
其中$Gini(D,A_1=3)$最小,所以$A_1=3$是$A_1$的最优切分点
求特征$A_2$的基尼指数
$$
Gini(D,A_2=1) = \frac{3}{10}[2\times\frac{3}{3}\times(1-\frac{3}{3})] + \frac{7}{10}[2\times\frac{1}{7}\times(1-\frac{1}{7})]=0.17
$$
$A_2$只有一个切分点即$A_2=1$
求特征$A_4$的基尼指数
$$
Gini(D,A_4=1) = \frac{1}{10}[2\times\frac{1}{1}\times(1-\frac{1}{1})] + \frac{9}{10}[2\times\frac{3}{9}\times(1-\frac{3}{9})]=0.4\\
Gini(D,A_4=2) = \frac{5}{10}[2\times\frac{3}{5}\times(1-\frac{3}{5})] + \frac{5}{10}[2\times\frac{1}{5}\times(1-\frac{1}{5})]=0.4\\
Gini(D,A_4=3) = \frac{4}{10}[2\times\frac{0}{0}\times(1-\frac{0}{0})] + \frac{6}{10}[2\times\frac{4}{6}\times(1-\frac{4}{6})]=0.27
$$
其中$Gini(D,A_4=3)$最小,所以$A_4=3$为$A_4$的最优切分点
在4个特征中,$Gini(D,A_2=1)=0.17$最小,所以选择$A_2$为最优特征,$A_2=1$为其最优切分点。其中$A_2=1$的结点包含数据3、13、14,$A_3 \neq 1$结点包含数据1、2、5、6、7、12、15。$A_2=1$结点内数据类别相同,所以形成叶子结点。对$A_2 \neq 1$结点内数据类别相同,所以形成叶子结点。
到此,CART树生成完毕。可以发现与之前按照ID3算法所生成的决策树一样,如下图。
参考
- 机器学习实战,人民邮电出版社
- 统计学习方法,清华大学出版社