简介
p4也是车道检测,可以说是p1的升级版。p1只是使用了简单的边缘检测和直线检测进行直线车道信息提取,并未考虑摄像头造成的畸变以及车道不是直线的时候如何进行车道检测,这节课在之前的基础上进行了延伸,过程中会用到更多计算机视觉处理技术。
处理流程
处理流程如下所示:

棋盘标定
在使用摄像设备进行图像拍摄的时候往往会有畸变误差,这些畸变误差分为两类:
径向畸变:由于透镜形状等原因造成,距离透镜光学中心越近畸变越小,越靠近透镜边缘畸变越严重。
切向畸变:由于摄像设备安装时不完全平行于图像平面造成的;
消除畸变可以采用棋盘标定来实现,通过检测棋盘的角点,获取校正系数,将其保存,用于后续实际拍摄图像的畸变校正。
代码如下
1 | #coding:utf-8 |
角点标记的效果如下

径向畸变校正
先展示一下未处理过的照片和畸变校正后的照片效果

可以看到左图边缘被弯曲的线条,在右图中被修正为平行线条。对于实际道路的图片,效果如下:

代码示例如下:
1 | #coding:utf-8 |
透视畸变校正
车载摄像头是固定在车上的,由于拍摄视角问题(摄像头与道路不垂直),拍摄出的照片有透视畸变,即近大远小,和美术的透视原理类似。
透视变换可以消除透视畸变,简而言之就是转化为鸟瞰图。其原理如下:取得畸变图像的4个点坐标和目标图像的4个点坐标,通过两组坐标计算出透视变换的变换矩阵,之后对整个图像执行变换,就实现了对图像的校正。
畸变图像需要进行透视变换的区域坐标分别为(580,460),(740,460),(280,680),(1050,680),在图上的区域如下

透视变换代码如下
1 |
|
经过透视变换,图像转换为

边缘检测
与p1类似若想提取车道信息,需要二值化处理、边缘检测、roi区域提取,但是p4的处理过程会有不同。
对于p1,直接读入灰度图像然后进行canny边缘检测,这样做有两个问题。首先是颜色检测,车道线条往往有不同的颜色,对于RGB格式来说,某些颜色在特定通道下检测效果不好,比如黄色车道线在Blue通道下是这样的

黄色分量在blue通道下辨识度不是很高。为了更好的进行颜色检测,可以把RGB格式转化为HLS格式,即使用色相(Hue)、饱和度(Saturation)、亮度(Lightness)表示颜色,可以获得更好的效果。
第二个问题是canny检测虽然能够获得很好的效果,但是它会把车道外其他部分的边缘提取出来,这些信息对于我们来说并没有用。考虑到车在行驶过程中,车道基本是垂直于车子,所以可以采用sobel算子提取x方向上的梯度,实现垂直方向上车道的检测。
代码如下
1 | def edge_detection(image,sobel_kernel=3,sc_threshold=(110, 255), sx_threshold=(20, 100)): |
检测效果如下:

接下来进行roi区域提取
1 | def roi(img,vertices): |
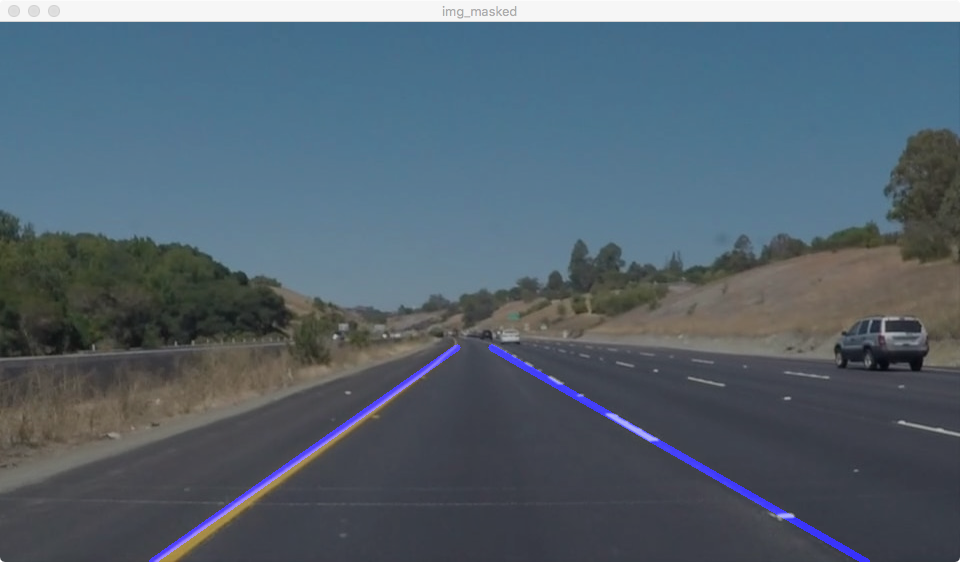
最后得到的车道图像为

车道标记
上个步骤结束后,我们找到了车道的大致范围,下面需要对这些点进行过滤,然后将其连成车道线。
确定中线范围
首先找到车道的中线作为搜索的起始点,由于车道有一定的弯曲,我们可以使用图片的下半部分画出直方图,查找其最大值位于x轴的位置。

1 | #获取直方图,得到车道大致位置 |
大致能确定左车道中心线大概在x=250,右车道中心线大概在x=1000的位置。
定义搜索框
在y轴方向上使用9个搜索框从图片底部向图片上部进行搜索,其宽度为80像素。
1 | #设置滑动窗口个数 |
过滤非零像素点
把不符合要求的点过滤掉,只保留窗口范围内的非零像素点,并调节搜索中线位置。整个过程如下

1 | #左车道搜索起始点 |
车道线拟合
拿到了车道像素点后,使用数学方法对其进行二次函数拟合。为了后续处理,还需要计算拟合曲线上的坐标。效果如下

1 | #拟合左车道曲线 |
标记车道范围
先在鸟瞰图上标记车道范围,然后映射到透视变换前的图像上。

1 | # 复制一份输出图像 |
处理视频
处理完单张图像,处理视频,效果对比如下
效果如下
- 原始视频
- 处理后视频
总结
这节课难度比前几节课略大,需要用到的图像处理手段有些复杂,需要一定时间消化理解,部分细节性技术后续会单开文章专门介绍,这部分代码参考Term-1-p4-advanced-lane-lines